
Introduction
Machine Learning is everywhere, and often in places you wouldn’t expect, including Siri, Google Searches, Retail Recommendations, Email Marketing, etc. Machine learning is also older than people think, despite existing in the young software industry. Portfolio managers, and quantitative financial analysts have been using these techniques to make gains in their business for a while now, but without much formality, or organization.
It seems strange to say, but this used to be the same case for most Computer and Information Technology industries. We forget how young the Software Industry is. We forget how new the Internet is. These systems have folded so easily into our lives, we barely remember what life was like before them.
Now, we should remember that coding standards, testing frameworks, infrastructure allocation, resource monitoring, and all the elements and principles that defined Good Software Practices and Development Operations took a long time to chaotically coalesce into a specialty or craft. But, once these principles began to centralize on an area of expertise, practitioners and professionals began specializing, thus formulating the field of DevOps as we know it today.
Machine Learning as a practice is benefitting directly from this earlier development to the Software Field as a whole, and like a younger brother, has inherited the same tools its old brother developed—this time we called it MLOps, because brothers just have to be different.
Before MLOps, companies spent countless manual hours monitoring and defending against horrible, business-breaking scenarios. Did our model drift? What’s the latest run look like? Has our training data changed in nature? What about the on-the-ground truth? These are the racing questions that face owners of Machine Learning products. MLOps is designed to handle these questions in an organized way, while making sure ML models are effectively and efficiently running in production, in order to defend against such nightmare scenarios for the Business.
Some Example Nightmare Scenarios
Imagine a small investment firm is managing its portfolio using its proprietary Portfolio Risk Model. The allocation of nearly everything in your portfolio is based on this model. Now, let’s imagine something changes—the underlying assumption, new lending laws, major market changes, whatever! Regardless, your model is now giving you “incorrect” predictions. The potential is two sided—in the worst case, the firm could be insolvent with a single price swing; or this firm could be underperforming for its clients, missing out on big windfalls and big management fees. These are both devastating consequences.
Now imagine a large online retail brand selling denim jeans and other denim clothing products. In order to increase conversions, they’ve implemented a product recommendation engine and surfaced it to a few places on the online retail site. However, after a few weeks, conversions are down, because you find out that your female shoppers were getting male jean sizes recommended. We’re not sure how this happened, but now, these recommendations have caused abandonment.
MLOps has been specifically designed to guard against these scenarios, which most call “Model Drift”. Model Drift can happen for a number of reasons, but all can be detected as the accuracy of the model decreases, as the underlying pattern “drifts” away from the pattern your model thinks is true. By monitoring and testing the accuracy of the models against new data, you can save yourself from serving inaccurate, or worse, entirely inappropriate predictions.
What is MLOps Exactly?
The value of MLOps can be stated directly by a fairly conventional definition, which I’ve paraphrased from the Continuous Delivery Foundation’s Special Interest Group on MLOps’ definition:
MLOps is practiced when Machine Learning assets are treated consistently with all other software assets within a CI/CD environment. Additionally, Machine Learning models are deployed alongside the services and assets that wrap them up, and/or the services that consume them as a part of a single release process.
Given this definition we can explicitly list the defining principles of MLOps:
- All machine learning assets are stored in a code repository and are versioned in that repository. Machine Learning developments should be enforced to follow the merging and change logic which defines how code makes it into the repository.
- Since all assets are versioned, this should include the data used for training, since this data is key to recreating the model found in the repository. Admittedly, this is perhaps the most difficult area to account for.
- These assets should be contained with pipeline and infrastructure requirements that will build the Machine Learning service or product using a Continuous Delivery Pipeline.
- As a part of the pipeline, the model should be tested after training. These test results should meet some performance threshold, before being ready for production.
- Models have their results tracked and stored after each training iteration and release, and these results should be monitored for significant change. The performance metrics that we care about should be measures of predictive power. Often, the model best defines the metrics that should be monitored. At the minimum, your distribution of predictions against the data inputs should be tracked, and monitored for drift.
Since MLOps is a process and a workflow, there are levels of complexity and automation to achieve. Companies should work to “level up” their MLOps capabilities as quickly as possible away from a purely manual process. Google wrote a wonderful article defining the levels of MLOps. They defined the levels as such:
- Level 0 – Fully Manual – This place is defined as having a hard line between the Machine Learning development and the operations process. As well as a fully manual piece for getting a new model checked into the repository or registry. Each step between model production, registration to the repository, and delivery to production is something that must be performed by a Data Team member.
- Level 1 – Automated ML Pipeline – This still consists of a manual separation between the testing and development environment, and the production environment. However, the development and testing pipeline for the Machine Learning piece is well automated and robust.
- Level 2 – Fully Automated CI/CD and ML Pipeline – The End Goal.
No matter which level you or your organization is at, you can still be effective when employing these concepts and principles. The higher levels of automation just give you that much more confidence and peace of mind, which is a worthwhile investment as your organization’s data needs mature.
Another unspoken benefit should be addressed, despite the tensions that exist. Like all little brothers, Data Science has been the annoying monkey on the Software Devs and DevOps team’s backs. Whenever Data Science was ready for production, the Traditional Software teams shuttered to think about the refactoring needed to land the model on production infrastructure. Always cleaning up after little brother can strain relationships and breed animosity, which could eventually spill into the work product. With a little automation to empower the Data Science team, the Traditional Software teams can feel confident that “little brother is finally all grown up.”
Where Rubber Meets the Road – Designing our MLOps Workflow
If we want to achieve the MLOps Level 2 Nirvana, we need to understand our ideal state and the pieces we need to get there. Below is a diagram of a Level 2 pipeline as described by the aforementioned Google article and others at the Continuous Delivery Foundation.
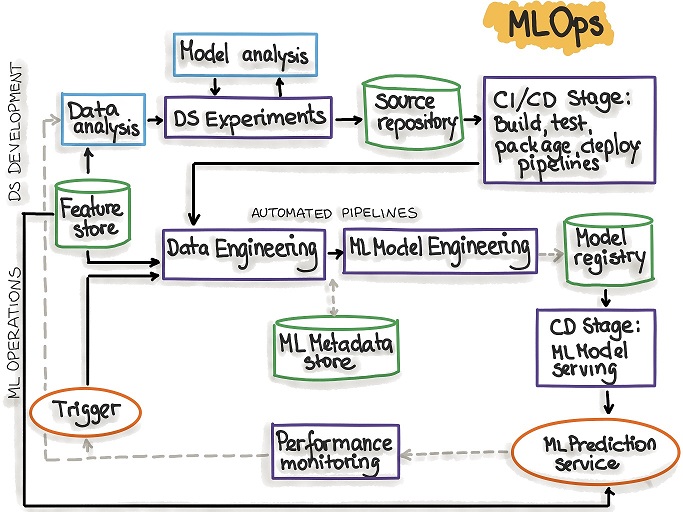
Figure 1 – Level 2 MLOps (Fully Automated CI/CD) from ml-ops.org.
Looking at the diagram of our Goal State, we can define a few stages and their outputs:
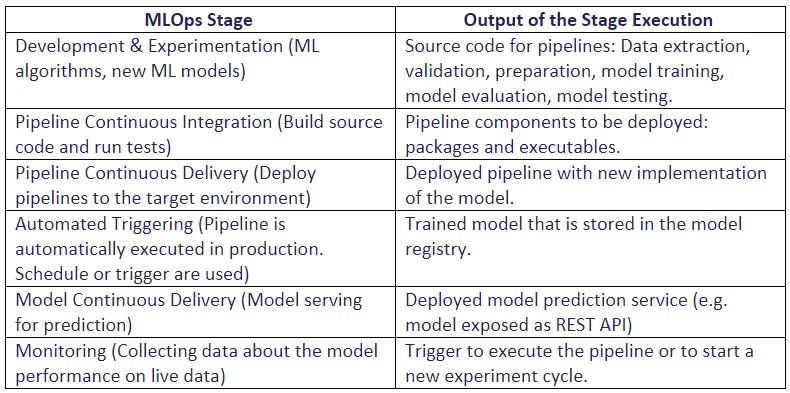 Table 1 – MLOps Stages (ml-ops.org)
Table 1 – MLOps Stages (ml-ops.org)
Given these stages, we have a few components we need to implement to make this whole thing work:
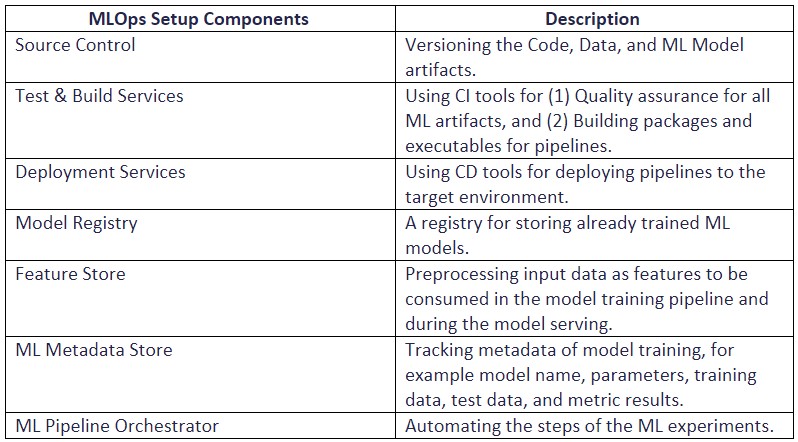
Table 2 – MLOps Components (ml-ops.org)
Story Time – Bob commits to a Model
To illustrate how this process works more concretely, let’s consider Bob and his model.
Bob’s New Feature
Bob has been adding a new feature to the model. This new feature is some arbitrary change for the purpose of our story. Now that he’s done, Bob has the new feature and has built the updated model on his local working directory within the repository where the model is located. Now, Bob commits his code changes to the repository and pushes those changes to the Remote Source Control Server on his feature branch.
CI/CD Build and Test
Given the changes to this model, the CI/CD services kick off the pipelines. These pipelines kickoff the build, train the model, run tests against the model, report on accuracy, and then allow a “pass or fail” based on the accuracy thresholds your organization has setup for your models. These results are stored in the Model Metadata Store for your team’s records. If the model fails the tests for any reason, then the changes are rejected and Bob should do some more development on the feature until his branch is passing those tests. Once the model passes our testing, then the model is shipped down the deployment pipeline.
Model Deployment and Storage
Since the model has passed through the testing phase, Bob merges his changes into the production branch. At this point, the Continuous Delivery pipelines kick into high gear—production resources are allocated, and while those are built, the model is placed into the model registry and tagged as the latest version. Once the production resources are ready, those resources pull the new model from the registry, and kick off the service as intended. Bob’s new model is Live and in Production!
Monitoring and Iteration
For now, Bob’s job is done. But tomorrow, he’s going to have to pay attention to his model as it serves live customers. Good monitoring solutions will give Bob the ability to see what predictions his model served, and what input data produced that output from the service. This is possibly the most valuable and important piece in the entire MLOps process. If Bob’s feature doesn’t behave in the wild, like it did in both his local testing and on the CI testing suite, then he needs to know, and he needs to know now. That way he can fix it if things go wrong, and Bob can continue to develop other models which provide value to his stakeholders and the business at large, with the confidence that he’ll know if something needs to be addressed.
Component Details
Source Control & Versioning
This component aims to treat all of our development assets which produce the model as first-class citizens of a Software Engineering environment. Since we care so much about these assets, we will employ good development practices regarding feature branching and development, and we will tag new versions of the repository as important changes to these assets are collected, tested, and then released with the new version tag.
ML Development & Experimentation
Because we have good source control and versioning, the development of new features or experiments within the development phase, should be handled by the branching convention within your Software Engineering teams. MLOps is how we bring Machine Learning and Data Science closer to traditional Software Development streams.
Continuous Integration & Testing
At the point where new Model code is ready to push to the next version, we should perform a litany of tests for completeness:
- Data Validation – Is the input data what we expect it to be?
- Feature Validation – Are the features we’re using what we expect them to be? Are they as correlated with our other features as they were last time?
- Unit Tests for Feature Creation Code – If the code makes transformations to the feature data, we should test those transformation algorithms with unit tests.
- Accuracy And Precision Testing – Does the model meet our performance criteria to be deployed?
- Infrastructure Testing – Is the provisioned service scalable? Can it take a stressful load of traffic?
Monitoring
Now that we’ve got an ML model through the pipeline and it’s out in the wild, we need to continuously monitor for changes, or unexpected conditions in the production environment. Be on the Lookout for:
Numerical Stability of the Model – Be sure we’re not serving Nulls or NaN’s or other nonsensical outputs.
Regression Performance or Drift – Be sure the model isn’t drifting in its output, and this strategy is going to be dependent on the model’s design. This strategy must be established ahead of deployment to production.
Data Schema or Out of Range Values – Be sure the range of input values in production match the range of values you trained on. If the model receives something it doesn’t expect, it will produce something you didn’t expect as well.
Useful Tools – “It’s Dangerous To Go Alone! Take This.”
While these stages are simple in concept, the details of execution and the underlying architectural details really can bog down a team. This is why linking several tools together is a common practice for MLOps architects.
We don’t want you to “Go Alone”, so for each MLOps component we’ve provided a list of tools which have been well rated and suggested in many of the articles and white papers concerning the topic of MLOps.
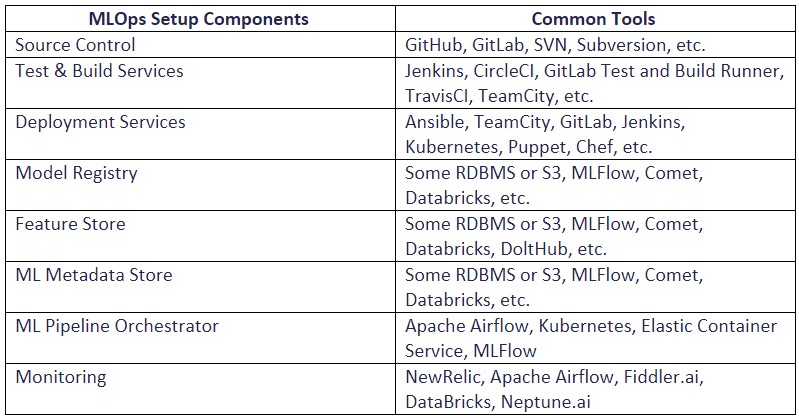
Table 3 – Commonly Used Tools for Each MLOps Stage
Conclusion
MLOps is a burgeoning new field that has the power to unite software and data teams. For too long, Software Engineers have quietly dreaded when the Data Science team was “ready for production.” Weeks of model development and research was now going to be weeks of refactoring to make the same results production ready. But as we approach Machine Learning with the principles of DevOps and integrate MLOps into our process, we can encourage these teams to collaborate and create new efficiencies for the Business and remove headaches and bottlenecks which plagued the relationship before.
At eSage Group, we’ve been encouraging our clients and customers, who employ us or their own teams for data science tasks, to seriously implement these MLOps workflows. Clients and companies who have taken this up, have seen immediate performance increases and efficiency gains, just from their Data Team’s ability to produce. We can’t wait to hear how much it’s affected their bottom line.
If you’re interested in Machine Learning and the Operations side of Data Science, reach out and book a free consultation with eSage Group. And stay tuned for more detailed content on the cutting edge of Machine Learning Operations.
Interesting Related Reads
- https://ml-ops.org/content/mlops-principles
- https://github.com/cdfoundation/sig-mlops/blob/master/roadmap/2020/MLOpsRoadmap2020.md
- https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- https://towardsdatascience.com/machine-learning-monitoring-what-it-is-and-what-we-are-missing-e644268023ba
- https://towardsdatascience.com/how-to-detect-model-drift-in-mlops-monitoring-7a039c22eaf9